在 Google Search Console (GSC) 中,“已发现 - 尚未编入索引”(Discovered - currently not indexed) 和 “已抓取 - 尚未编入索引”(Crawled - currently not indexed) 是两种不同的状态,如果你的站点也有这两种状态就需要注意优化了。
🔍 已发现 - 尚未编入索引 (Discovered - currently not indexed)
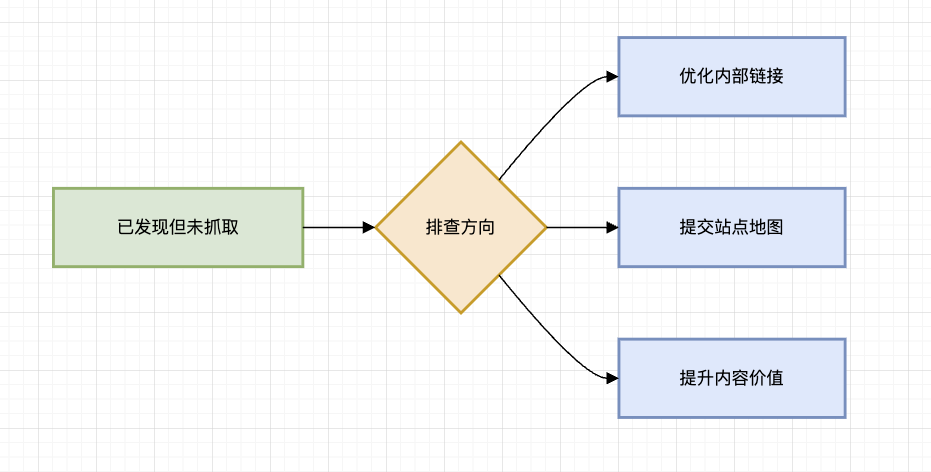
Google 知道页面存在(通过 sitemap、其他页面的链接或手动提交),但尚未安排爬虫抓取该页面。 原因分析: 抓取预算不足(网站规模过大,Google 优先抓取更重要的页面) 新页面刚被发现,在爬取队列中等待 网站结构问题(内部链接薄弱,页面孤立)
解决方案:
🤖 已抓取 - 尚未编入索引 (Crawled - currently not indexed)
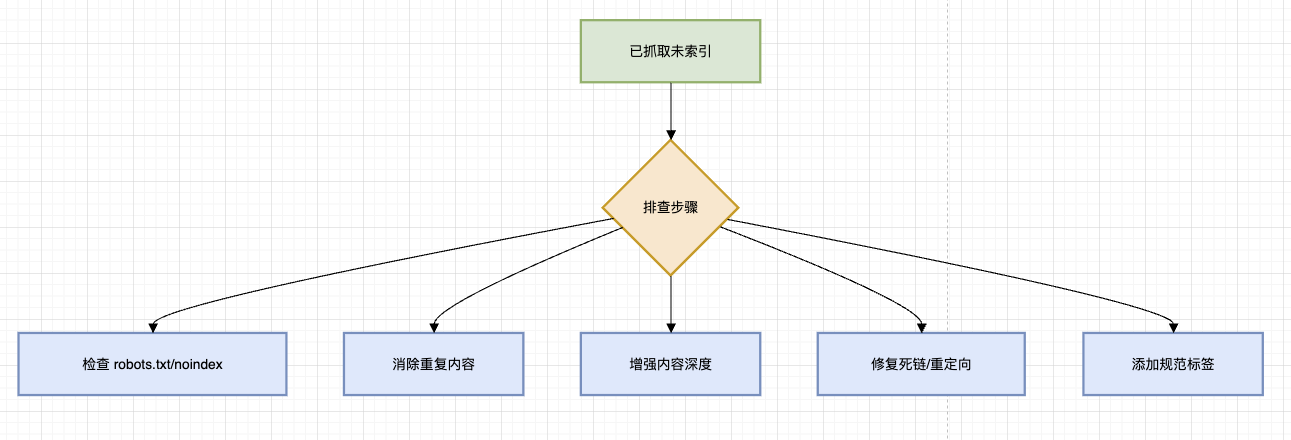
Google 已抓取页面内容,但故意不将其编入索引(Index)。
根本原因:
原因类型 具体问题 质量问题 内容重复/低质/空洞、与搜索意图不匹配 技术问题 noindex标签、robots.txt 拦截、软404、规范链接受阻资源限制 Google 认为该页面价值不足,优先索引其他页面 惩罚风险 过度优化、垃圾外链、被算法判定为低质量 解决方案:
💎 核心区别在哪?
| 特征 | 已发现 - 尚未编入索引 | 已抓取 - 尚未编入索引 |
|---|---|---|
| Google 处理阶段 | 发现阶段 → 等待抓取 | 抓取完成 → 拒绝索引 |
| 问题严重性 | ★★☆☆☆ (中低) | ★★★★☆ (高) |
| 主要原因 | 爬虫优先级低、新页面 | 内容质量问题、技术性拦截 |
| 是否分析过内容 | ❌ 未读取页面内容 | ✅ 已分析内容但判定不达标 |
| 解决方向 | 提升可发现性 | 解决内容/技术缺陷 |
🛠️ 实战处理建议
针对 "已发现" 状态:
加强内部链接:确保每个页面至少被2-3个权威页面链接 提交 Sitemap:在 GSC 手动提交 XML 站点地图 加速抓取:对关键页面使用,URL 检查工具 → 请求编入索引:(https://support.google.com/webmasters/answer/9012289)
针对 "已抓取" 状态:
第一:技术审计
# 快速检测工具链
curl -I https://example.com/page # 检查HTTP头
Chrome DevTools → 查看网络请求 # 验证noindex/规范标签第二:内容优化
添加独特数据(统计表、案例研究) 覆盖更全面的关键词意图(如补充 "如何做"、"对比" 等内容维度)
第三:权限提升
获取高质量外链 → 提高页面权威性 减少低质页面 → 集中爬取预算到核心内容
⚠️ 如果有大量页面长期处于 "已抓取未索引",需警惕网站整体质量被降权。
🌐 补充说明
时效性:两种状态都可能持续几天到几周,若超过1个月未变化则需干预 优先级:重点处理 高价值页面 的问题(如产品页、转化页) 监控工具:
通过针对性解决这两种状态的问题,可显著提升网站在 Google 的可见度。更多细节参考 Google 官方索引指南(https://developers.google.com/search/docs/beginner/get-indexed)。