谷歌新版 Gemini 可以处理更大量的数据
谷歌 DeepMind 今天推出了其下一代强大的人工智能模型 Gemini,该模型处理大量视频、文本和图像的能力得到了增强。
它是Google 在 12 月份宣布的三个 Gemini 1.0 版本的改进,其大小和复杂性从 Nano 到 Pro 到 Ultra。(上周,谷歌在其许多产品中推出了 Gemini 1.0 Pro 和 1.0 Ultra 。)Google 现在向精选的开发人员和企业客户发布了 Gemini 1.5 Pro 的预览版。该公司表示,中端 Gemini 1.5 Pro 在性能上与其之前的顶级型号 Gemini 1.0 Ultra 相匹配,但使用的计算能力较低(是的,这些名称令人困惑!)。
至关重要的是,1.5 Pro 型号可以处理来自用户的大量数据,包括更大的提示。虽然每个 AI 模型在可以消化的数据量上都有上限,但新 Gemini 1.5 Pro 的标准版本可以处理多达 128,000 个令牌的输入,这些令牌是 AI 模型将输入分解成的单词或单词的一部分。这与GPT-4的最佳版本(GPT-4 Turbo) 相当。
然而,有限的开发者群体将能够向 Gemini 1.5 Pro 提交最多 100 万个代币,这相当于大约 1 小时的视频、11 小时的音频或 700,000 字的文本。这是一个巨大的飞跃,使得我们可以做目前其他模型无法做到的事情。
在谷歌展示的一个演示视频中,研究人员使用百万代币版本向模型提供了一份 402 页的阿波罗登月任务记录。然后,他们向双子座展示了一张手绘的靴子草图,并要求其识别该图画所代表的记录中的时刻。
“这是尼尔·阿姆斯特朗登陆月球的那一刻,”聊天机器人正确地回答道。“他说,‘个人的一小步,人类的一大步。’”
该模型还能够识别幽默时刻。当研究人员要求在阿波罗记录中找到一个有趣的时刻时,它找到了宇航员迈克·柯林斯(Mike Collins)将阿姆斯特朗称为“沙皇”。(可能不是最好的台词,但你明白了。)
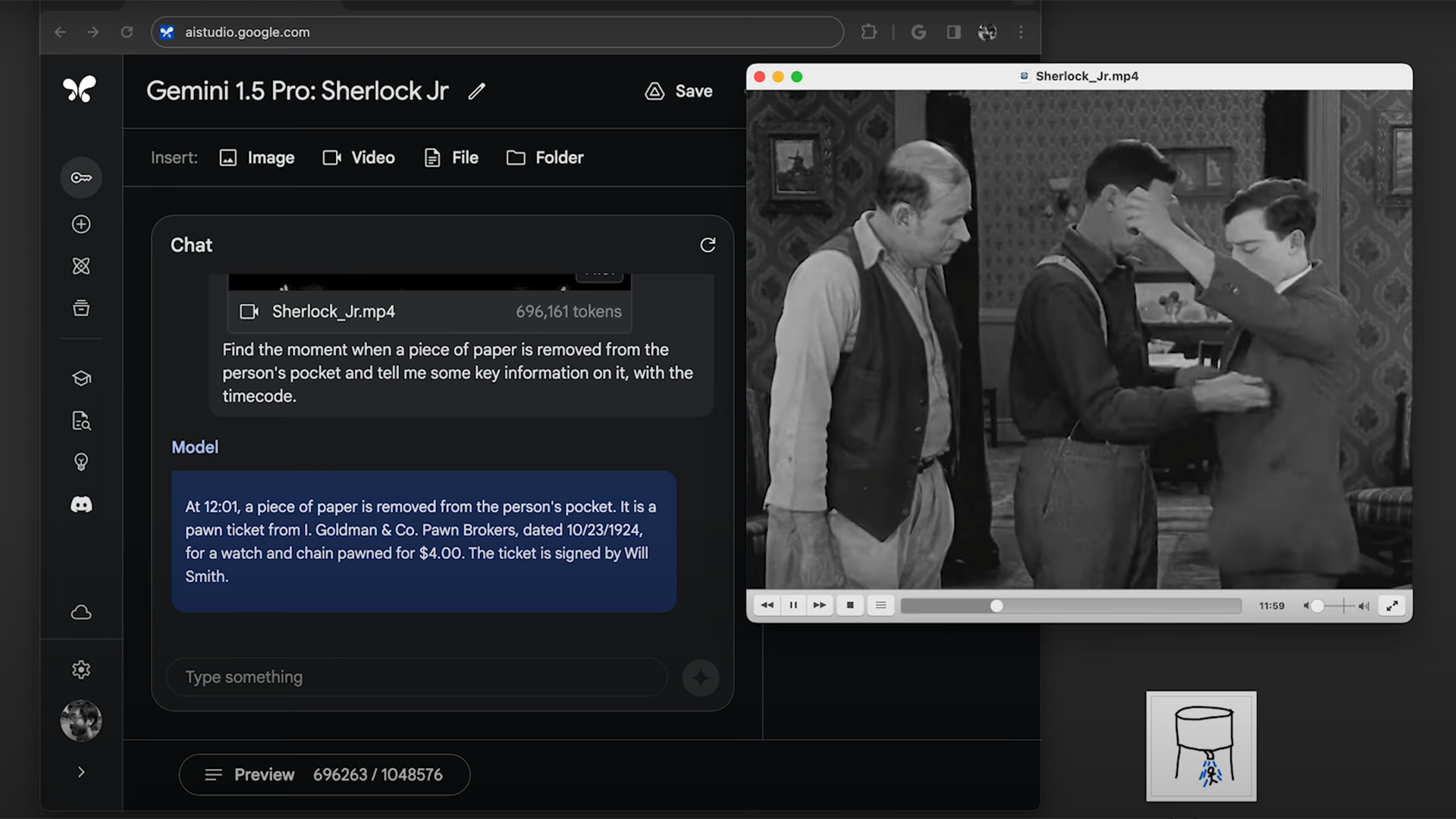
在另一次演示中,该团队上传了一部由巴斯特·基顿主演的 44 分钟无声电影,并要求人工智能识别一张纸上的信息,该纸在电影中的某个时刻从角色的口袋中取出。不到一分钟,模型就找到了场景,并正确回忆出了纸上写的文字。研究人员还重复了阿波罗实验中的类似任务,要求模型根据图画找到电影中的场景。也完成了这个任务。
谷歌表示,它对 Gemini 1.5 Pro 进行了开发大型语言模型时通常使用的一系列测试,包括结合文本、代码、图像、音频和视频的评估。研究发现,1.5 Pro 在 87% 的基准测试中优于 1.0 Pro,并且在所有基准测试中或多或少与 1.0 Ultra 相匹配,同时使用更少的计算能力。
谷歌表示,处理更大输入的能力是所谓的专家混合架构取得进展的结果。使用这种设计的人工智能将其神经网络分成多个块,仅激活与手头任务相关的部分,而不是立即启动整个网络。(谷歌并不是唯一使用这种架构的公司;法国人工智能公司 Mistral 发布了一个使用它的模型,据传 GPT-4 也采用了该技术。)
DeepMind 深度学习团队负责人 Oriol Vinyals 表示:“在某种程度上,它的运作方式很像我们的大脑,但并不是整个大脑一直都在激活。” 这种划分可以节省人工智能的计算能力,并且可以更快地生成响应。
艾伦人工智能研究所前技术总监奥伦·埃齐奥尼(Oren Etzioni)没有参与这项工作,他说:“这种在不同模式之间来回流动并利用它来搜索和理解的流动性非常令人印象深刻。” “这是我以前从未见过的东西。”
可以跨模式运行的人工智能将更类似于人类的行为方式。“人们天生就是多模式的,”埃齐奥尼说。我们可以毫不费力地在说、写、画图像或图表之间切换来传达想法。
然而,埃齐奥尼警告不要从事态发展中获得太多意义。“有一句著名的台词,”他说。“永远不要相信人工智能演示。”
一方面,目前尚不清楚演示视频遗漏了多少内容或从各种任务中精心挑选了多少内容(谷歌确实因其早期 Gemini 发布而受到批评,因为没有透露视频已被加速)。如果输入措辞稍作调整,模型也可能无法复制某些演示。Etzioni 表示,人工智能模型总体来说是脆弱的。
今天发布的Gemini 1.5 Pro仅限于开发者和企业客户。谷歌没有具体说明何时可以进行更广泛的发布。
